|
|
|
There are lots of ways of configuring your RAMADDA server.
Along with these configuration options there are a number of other
services that can be configured. See here for more information.
Most of these configuration options require setting one or more properties. These
can be added to any ".properties" (e.g., repository.properties)
file in your RAMADDA home directory.
|
ramadda.hostname=foo.edu
ramadda.google.tag=<your measurement ID>
ramadda.languages.enabled = true ##Set this to define the default language ##ramadda.language.default=esIf enabled then logged in users can set their default language. Also there will be a link shown in the upper right of every page to change the displayed language. The translations for each language are defined in a ".pack" file. There are language packs defined in the RAMADDA source (on Github) for Spanish, French and Chinese. You can define your own language packs and place them in the htdocs/languages directory under your RAMADDA home directory.
neon.api.key=YOUR KEY
#for google geocoding google.key= #For geocoding using the Here API from https://www.here.com/ #also for isoline and routing in the Intgerated Map Data Viewer (IMDV) here.key= #For geocoding from https://www.geocod.io/ geocodeio.key=
#for google geocoding google.key= #For geocoding using the Here API from https://www.here.com/ #also for route generation in the editable maps here.key= #For geocoding from https://www.geocod.io/ geocodeio.key= #show google streetview images google.streetview.key= #For accessing purple air sensor data #https://www2.purpleair.com/ purpleair.api.key= #for enabling sms access twilio.accountsid= twilio.authtoken= twilio.phone= #bureau of labor statistics bls.api.key= #fec fec.api.key= #used in the GTFS displays ramadda.uber.token= ramadda.lyft.clientid= ramadda.lyft.secret= #other... quandl.api.key= webhose.api.key= enigma.api.key= wolfram.api.key=
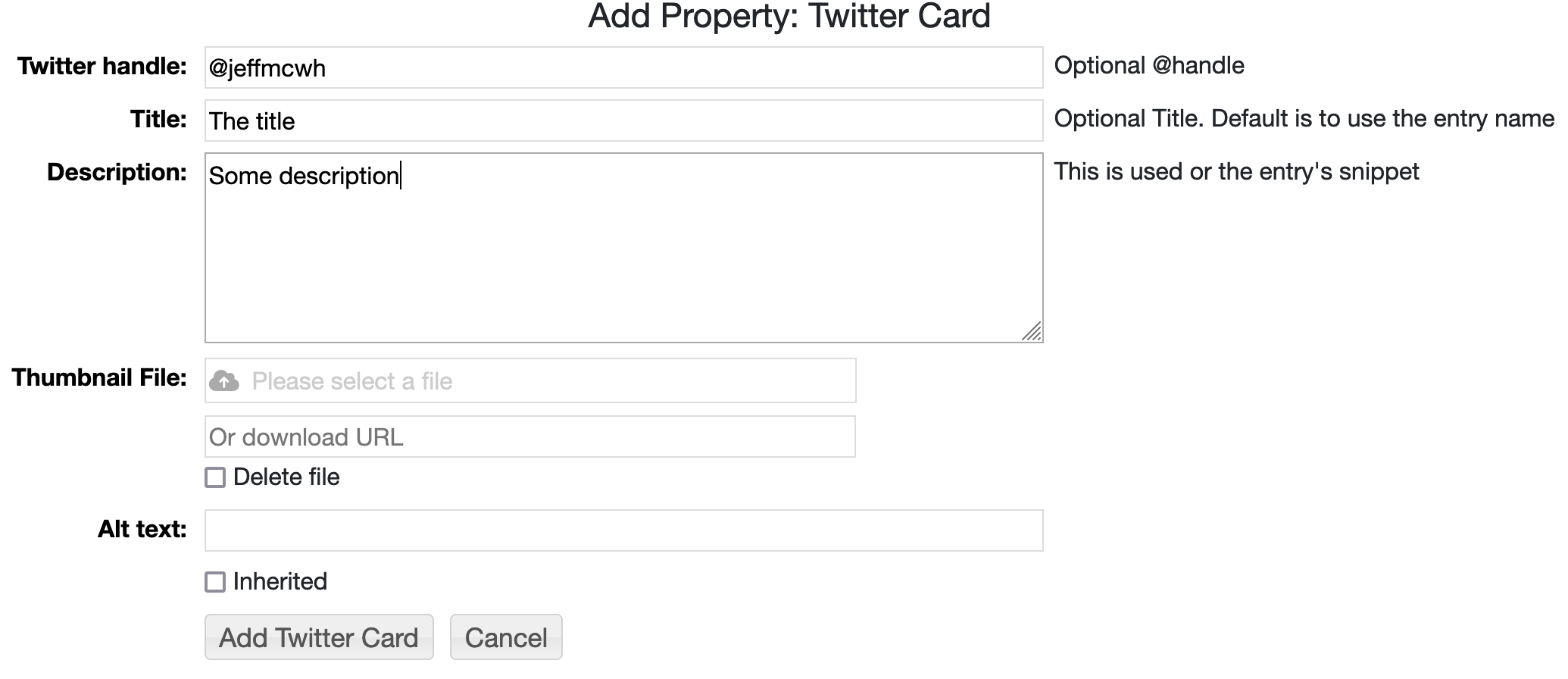
<meta name="twitter:card" content="summary_large_image"> <meta name="twitter:title" content="Salton Sea"> <meta name="twitter:description" content="This is an example..."> <meta name="twitter:image" content="https://ramadda.org/repository/metadata/view/Screenshot_2023-09-25_at_08-12-53_Salton_Sea_Map.png?element=1&entryid=0e3af72d-8be7-4f9d-933d-983fad440bba&metadata_id=b96d579f-d914-4d8a-bb04-78c5896a8243"> <meta name="twitter:creator" content="@jeffmcwh">By default the name of the entry is used for the title. If the entry has a Thumbnail image property attached to it then the Twitter Card will be an image. If the entry is an Image then the image will be used. Else it will just be a text summary. The entry's snippet is used for the description. There is also a Twitter Card property type that can be used to specify the title, creator, description and image. Under Add Property->Miscellaneous add the Twitter Card property:
ramadda.showtwittercard=false
@(github user=some_user_name) or: @(github owner=repository_owner repository=repository)The access to the Github API is rate limited. To increase the request rate create a personal access token through Github and set the following RAMADDA property:
github.token=your token
ramadda.cdnok=trueFor the core resources RAMADDA uses cdn.jsdeliver.net using the latest Github version tag, e.g.:
https://cdn.jsdelivr.net/gh/geodesystems/ramadda@6.60.0/...For other resources RAMADDA uses the standard CDN for the resource, e.g.:
https://code.jquery.com/jquery-3.3.1.min.jsThere are also a number of other flags
#Chunk all of the css together ramadda.css.all=true #Serve the javascript minified and chunked ramadda.minified=true #When displaying an entry serve up the beginning of the page before #any processing of the contents of the page ramadda.streamoutput=true #cache the web resources in memory ramadda.cachehtdocs=true
ramadda.contact=...You can add any other information for this page with:
ramadda.information=This is my server...RAMADDA also provides a security.txt file that follows the specification from https://securitytxt.org/. The URL is: /repository/well-known/security.txt.
ramadda.security.contact=mailto:youremail@foo.com
ramadda.httpheader1=<header name>:<header value> ramadda.httpheader2=<header name>:<header value> ...e.g: For specifying HSTS Strict-Transport-Security header you would do:
ramadda.httpheader1=Strict-Transport-Security:max-age=86400; includeSubDomainsOnce you restart your RAMADDA it is a good idea to check the headers, e.g. with curl:
curl -v "http://localhost:8080" > foo
ramadda.showjsonld=true
ramadda.logging.logactivityfile=trueWhen set various entry activities - view, file, data (providing data to a display) - are logged to a file: