| RAMADDA makes use of OpenAI's GPT API or Google's Gemini API
in a number of ways. Various metadata can be extracted from
documents and the wiki editor can make use of the LLMs to convert and create text.
|
Integration with Google's Gemini Model
Get an API key from
Anthropic and
set the property:
claude.api.key=your key
Integration with Anthropic's Claude Model
Get an API key from
Google and
set the property:
gemini.api.key=your key
Integration with OpenAI GPT
RAMADDA uses OpenAI's GPT API for extracting keywords and text summaries for documents
(PDF, Word, etc). To enable this you will need to register with
OpenAI and obtain an API key. They provide a free tier.
Once you obtain the API key add it to a
.properties file
in your RAMADDA home directory:
openai.api.key=<your key>
#To enable GPT4 (which comes with a higher cost) set:
openai.gpt4.enabled=true
Summary and Keyword Extraction
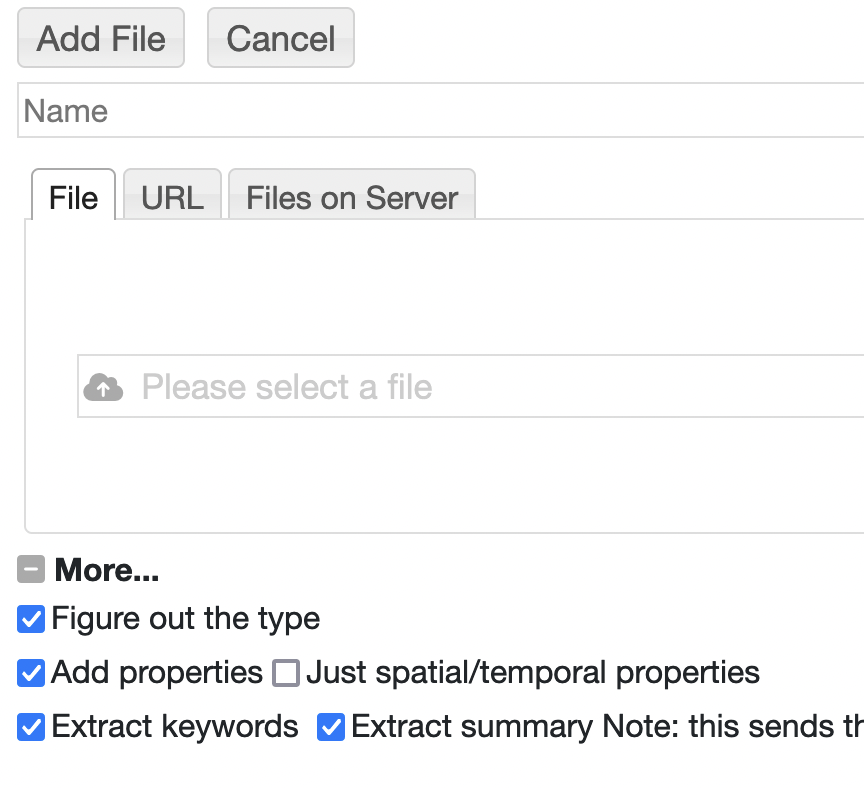
Now, when you go to add a document entry to RAMADDA under the "More..." section select
Extract keywords and/or Extract Summary. Any keywords extracted will be added as metadata
and the summary will be pre-prended to the new entry's description.
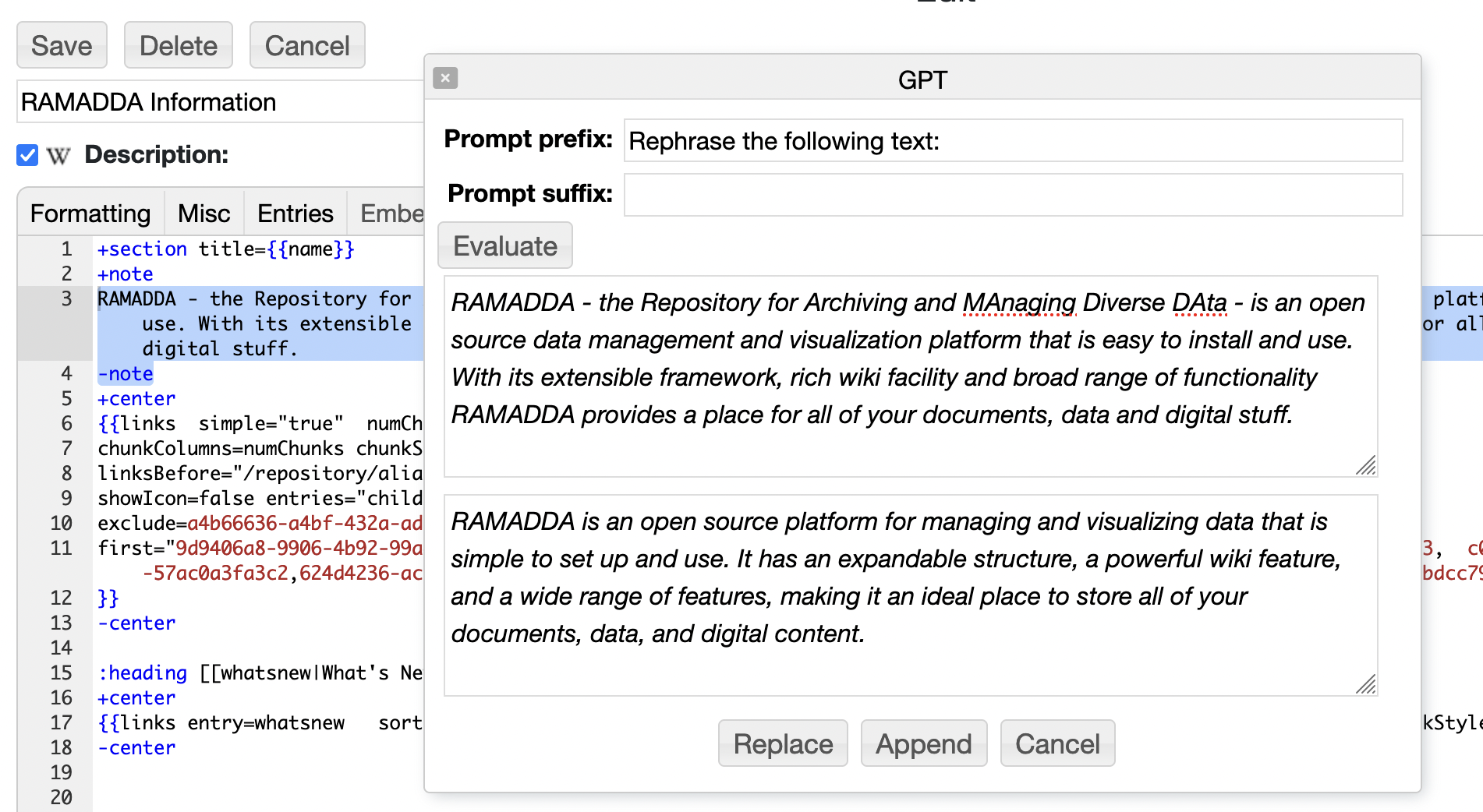
The Wiki editor provides an interface to the GPT api. If GPT is enabled there
will be a GPT link Under the Etc... menu. This brings up the below dialog. Any text
that is selected in the wiki editor will be added to the input area. When Evaluated the
prompts and the input text are sent to GPT and the result is placed in the Results area.
You can then either replace the selected text with the results or append the results.
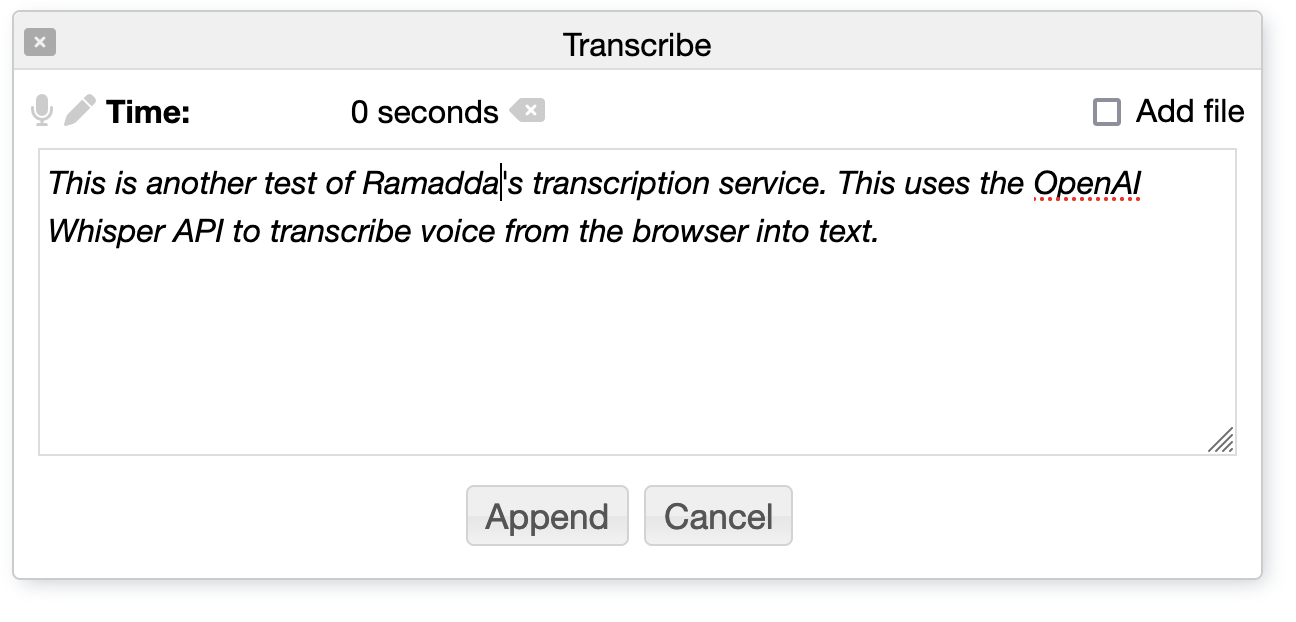
Audio to Text Transcriptions
Also under the Etc... menu is a Transcription service. You can record audio
through your browser and then the audio is sent to OpenAI's Whisper API for
transcription to text.
Note: this does not appear to work with Safari as the .mp4 audio file format Safari
creates is not accepted by OpenAI.